PlanetKit 5.2 voice quality snapshot report
In an article "Measuring voice quality in the LINE app" on the LY Corporation Tech Blog, we outlined three key areas for quantitatively measuring the voice quality of the LINE app: acoustic echo cancellation (AEC), frequency response, and loss robustness. Because the LINE app uses the VoIP module provided by LINE Planet for its voice call function, the same measurement method can be applied to assess the voice quality of LINE Planet.
Going forward, whenever a version of LINE Planet is released with improvements that affect voice quality, we will conduct performance measurements in the aforementioned areas. This will allow us to quantitatively determine voice quality and identify areas that have improved over the previous version or need further enhancement. We will refer to the voice quality measurement results of each version as a "voice quality snapshot".
This article represents the first in a series where we will compare and analyze voice quality snapshots across different versions of LINE Planet. It mainly deals with the results of comparing and analyzing voice quality snapshots of PlanetKit 5.1 and PlanetKit 5.2.
AEC performance
In this section, we conduct a quantitative assessment of LINE Planet's AEC performance. For explanations of terminology, measurement environment setup, and the measurement procedure, please refer to the "Measuring AEC performance" section of Measuring voice quality in the LINE app.
Measurement environment
AEC quality was measured using the test dataset for the year 2022 provided by AEC-Challenge and AECMOS.
The test dataset includes full-band audio data and consists of 800 audio data items divided into three types as follows:
- Double talk: 300 items
- Far-end single talk: 300 items
- Near-end single talk: 200 items
For the AECMOS measurements, we used the Run_1668423760_Stage_0.onnx model, which can be used for measuring the performance of full-band audio.
The tested versions of LINE Planet SDK are the latest version (PlanetKit 5.2) and the previous version (PlanetKit 5.1).
Related platforms and call types
The platforms and call types relevant to the quality covered by this test are as follows:
- Platforms
- Desktop (Windows, macOS)
- Call types
- 1-to-1 audio call
- 1-to-1 video call (voice only)
- Group audio call
- Group video call (voice only)
Measurement result
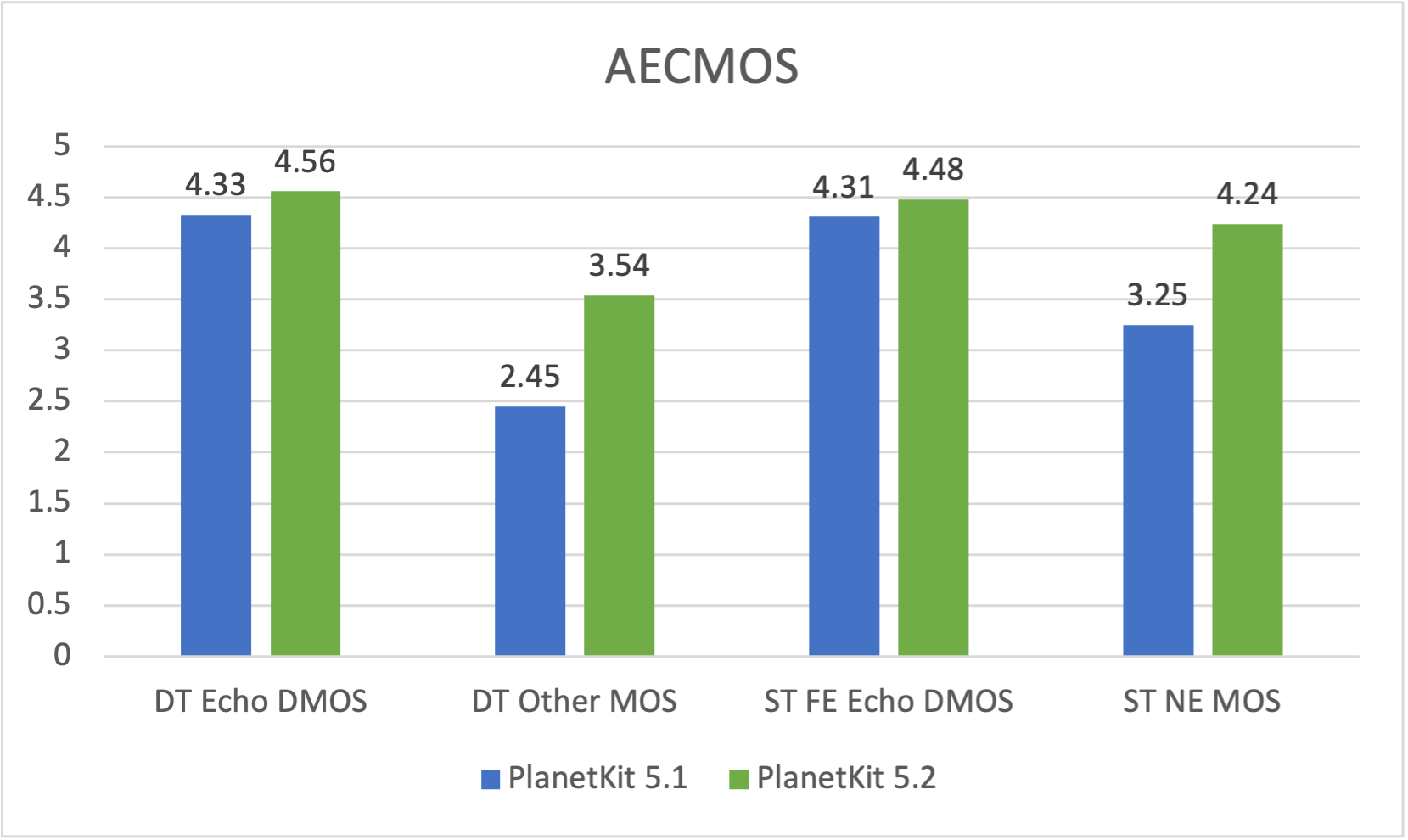
The measured AECMOS values are shown in the following figure. (out of 5.0 points)
Measurement result analysis
In PlanetKit 5.2, we have seen an increase in the scores of all performance metrics of AECMOS due to the application of AEC using machine learning technology. Notably, while it's common to encounter a trade-off situation where the more robustly the echo is removed, the more the voice quality is degraded, the AEC implemented in this version overcomes this trade-off. Consequently, the scores of all performance metrics have increased.
The improvements in each performance metric are as follows:
- DT Echo DMOS
- The score has increased by 0.23 points compared to the previous version. This indicates an enhanced capability to eliminate echoes that can occur in situations where two people are speaking at the same time.
- DT Other MOS
- The score has increased by 1.09 points compared to the previous version. This means that in situations where two people are speaking at the same time, users can now better recognize each other's sounds. As this metric is the most challenging to enhance, the AEC module of the previous version yielded very low scores. However, in this version, this aspect has seen significant improvement, leading to the largest increase in score.
- ST FE Echo DMOS
- The score has increased by 0.17 points compared to the previous version. This suggests an enhanced capability to eliminate echoes that can occur when only one person is speaking.
- ST NE MOS
- The score has increased by 0.99 points compared to the previous version. This indicates that the degradation of speech that can occur when two people speak at the same time in an echo-free environment has been mitigated. An echo-free environment refers to situations where the sound from the speaker cannot be transmitted to the microphone, such as when wearing earphones or a headset. In such environments, when two people speak simultaneously, the AEC module may incorrectly detect an echo even when no echo has occurred. If such an error occurs, the voice that should be transmitted to the other party is mistakenly identified as an echo and removed, leading to significant inconvenience during the call. It was analyzed that this phenomenon frequently occurs in the interpretation environment, and it was confirmed that most of the issues have been resolved in this version.
Further works
PlanetKit 5.2 showed an increase in the detailed performance metrics of AECMOS. Notably, it is meaningful that all performance metrics have increased, even though they have a trade-off relationship in which degradation inevitably follows when echo is removed.
However, while all other metrics showed scores above 4.0, DT Other MOS presented a score in the mid-3 range. Therefore, it is a priority to improve voice quality in situations where two people are speaking simultaneously.
When two people are speaking at the same time and the sound output from the speaker is quieter than the talker's voice, the voice is well preserved during the echo cancellation process. This results in a high score even in the current version. On the other hand, if the sound output from the speaker is louder than the talker's voice, a significant portion of the voice is removed during the echo cancellation process, leading to a lower score.
We are conducting ongoing research and development to address these issues, and we are also continuing our efforts to improve the quality of other metrics.
Frequency response
In this section, we conduct a quantitative assessment of LINE Planet's frequency response. For explanations of terminology, measurement environment setup, and the measurement procedure, please refer to the "Measuring frequency response" section of Measuring voice quality in the LINE app.
Measurement environment
A voice signal is transmitted from the sender side (A) to the receiver side (B), and the frequency response is measured by comparing the voice transmitted from A with the voice received in B.
The measurement environment is as follows.
- Sender side (A)
- Device: MacBook Pro M1
- OS version: macOS Ventura 13.4.1
- Audio device: VB cable
- Sending volume adjustment: -4 dB
- App version: LINE Desktop 8.4 (PlanetKit 5.2)
- Receiver side (B)
- Device: MacBook Pro Intel
- OS version: macOS Ventura 13.4.1
- Audio device: VB cable
- App version: LINE Desktop 8.4 (PlanetKit 5.2)
Related platforms and call types
The platforms and call types relevant to the quality covered by this test are as follows:
- Platforms
- Desktop (Windows, macOS)
- Mobile (iOS, Android)
- Call types
- 1-to-1 audio call
- 1-to-1 video call (voice only)
- Group audio call
- Group video call (voice only)
Measurement result
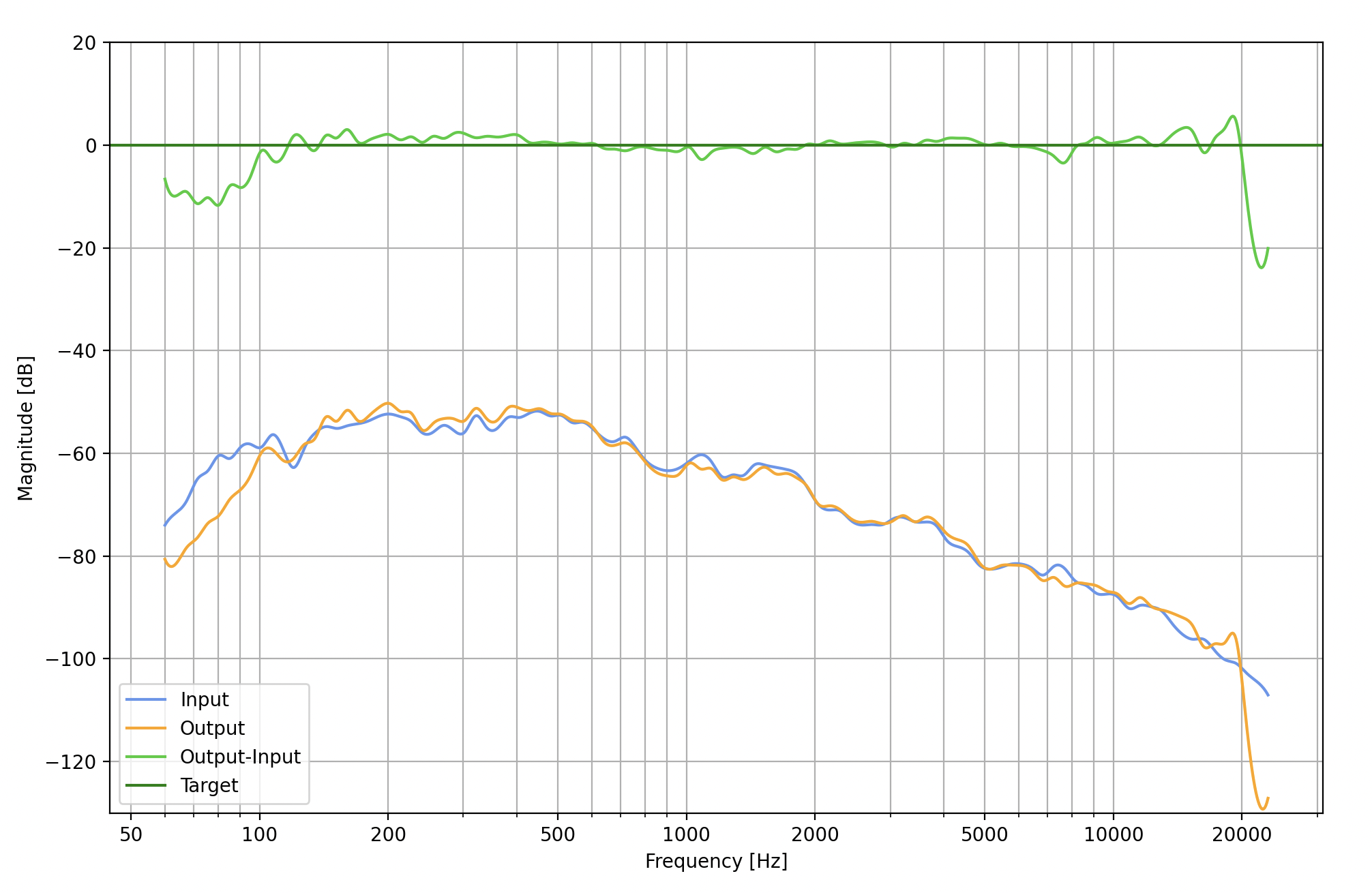
The measured frequency response is shown in the following figure.
Measurement result analysis
Through these frequency response measurements, we confirmed that PlanetKit 5.2 covers up to 20 kHz, the maximum frequency range that the human ear can perceive. Notably, we observed that the balance is maintained evenly across the overall frequency range. These characteristics enhance voice quality and clarity, facilitating more natural conversation for users.
The characteristics of the measured frequency response are as follows:
-
Attenuation at frequencies below 120 Hz
The signal magnitude tends to attenuate by 2 to 10 dB at frequencies below 120 Hz. Since this frequency range does not contribute to voice calls, the attenuation is intentional.
-
Boost at frequencies from 150 Hz to 350 Hz
The signal magnitude tends to boost by 0 to 3 dB at frequencies between 150 Hz and 350 Hz. This suggests a slight emphasis on the lower frequency range of the voice.
-
Attenuation at frequencies from 7 kHz to 8 kHz
There is a tendency for a 3 dB attenuation at frequencies between 7 kHz and 8 kHz. These frequencies represent part of the range that expresses fricative and sibilant sounds in speech. As a result, slight attenuation may occur in the 7 kHz to 8 kHz range of these sounds.
This is a characteristic of LINE Planet's voice signal processing, which treats signals below 8 kHz and above 8 kHz separately. The attenuation in the frequency contact area occurs during the process of combining these signals.
-
Frequency limit at frequencies above 20 kHz
There are no signals for frequencies above 20 kHz. Signals above 20 kHz exceed the range of audible frequencies. Consequently, LINE Planet does not transmit any information for the frequency range above 20 kHz.
Further works
Through frequency response measurements, we have confirmed that PlanetKit 5.2 evenly outputs voice input without distortion. Furthermore, we were able to find out the frequency characteristics through detailed analysis.
Among these characteristics, we observed an attenuation occurring in 7 kHz to 8 kHz of the frequency response, which would be an area for improvement. By addressing the attenuation that occurs between 7 kHz and 8 kHz, we can enhance the expression of detailed aspects of the voice, such as fricatives and sibilance. Therefore, if this issue is enhanced in future updates, users will be able to interact with higher voice quality.
The measurement results presented here were obtained on macOS, using a virtual audio device to minimize the influence of the audio device and surrounding environment. Different results may be observed when measurements are conducted in an environment (including app version, content type, transmission volume, OS, and audio device) that differs from the one used in this measurement.
For instance, different results may occur if the audio device in use (such as speakers or a microphone device) does not accurately represent low or high frequencies, or exhibits an uneven frequency response. On mobile devices, ultra-high frequency bands are often blocked by the OS, which may prevent the measurement of signals in these bands.
Furthermore, if the content does not primarily consist of voice, it might be perceived as noise and subsequently removed, potentially leading to different frequency response results.
Loss robustness
In this section, we conduct a quantitative assessment of LINE Planet's loss robustness. For explanations of terminology, measurement environment setup, and the measurement procedure, please refer to the "Measuring loss robustness" section of Measuring voice quality in the LINE app.
Measurement environment
We compared the voice quality in a packet loss environment between PlanetKit 5.2 and its previous version, PlanetKit 5.1, in the following environment:
- Common
- Network: Korea, KT, Ethernet
- Packet loss emulation: PacketStorm equipment was used. Random packet loss is applied to the uplink on the sender side.
- POLQA measurements: DSLA II equipment was used.
- Application
- Previous version: LINE Desktop 8.3 (PlanetKit 5.1)
- Latest version: LINE Desktop 8.4 (PlanetKit 5.2)
- Sender side
- Device: MacBook Pro M1
- OS version: macOS 11 Big Sur
- Receiver side
- Device: MacBook Pro Intel
- OS version: macOS 11 Big Sur
Related platforms and call types
The platforms and call types relevant to the quality covered by this test are as follows:
- Platforms
- Desktop (Windows, macOS)
- Mobile (iOS, Android)
- Call types
- 1-to-1 audio call
- 1-to-1 video call (voice only)
- Group audio call
- Group video call (voice only)
Measurement result
Description of metrics
- POLQA MOS
- POLQA is a global standard algorithm designed for the objective assessment of voice quality.
- Mean opinion score (MOS) is a measure used to assess voice quality.
- It is expressed on a scale of 1 to 5, where a higher score indicates a better voice quality.
- One-way delay
- We measure the time from when the voice signal is input to the device to when it is output and played on the receiving device.
- A large one-way delay makes two-way communication inconvenient, so the smaller the delay, the better.
- Data usage
- Recovering from packet loss requires the use of additional data, which increases data usage.
- It is preferable to minimize this because large data usage can cause network congestion.
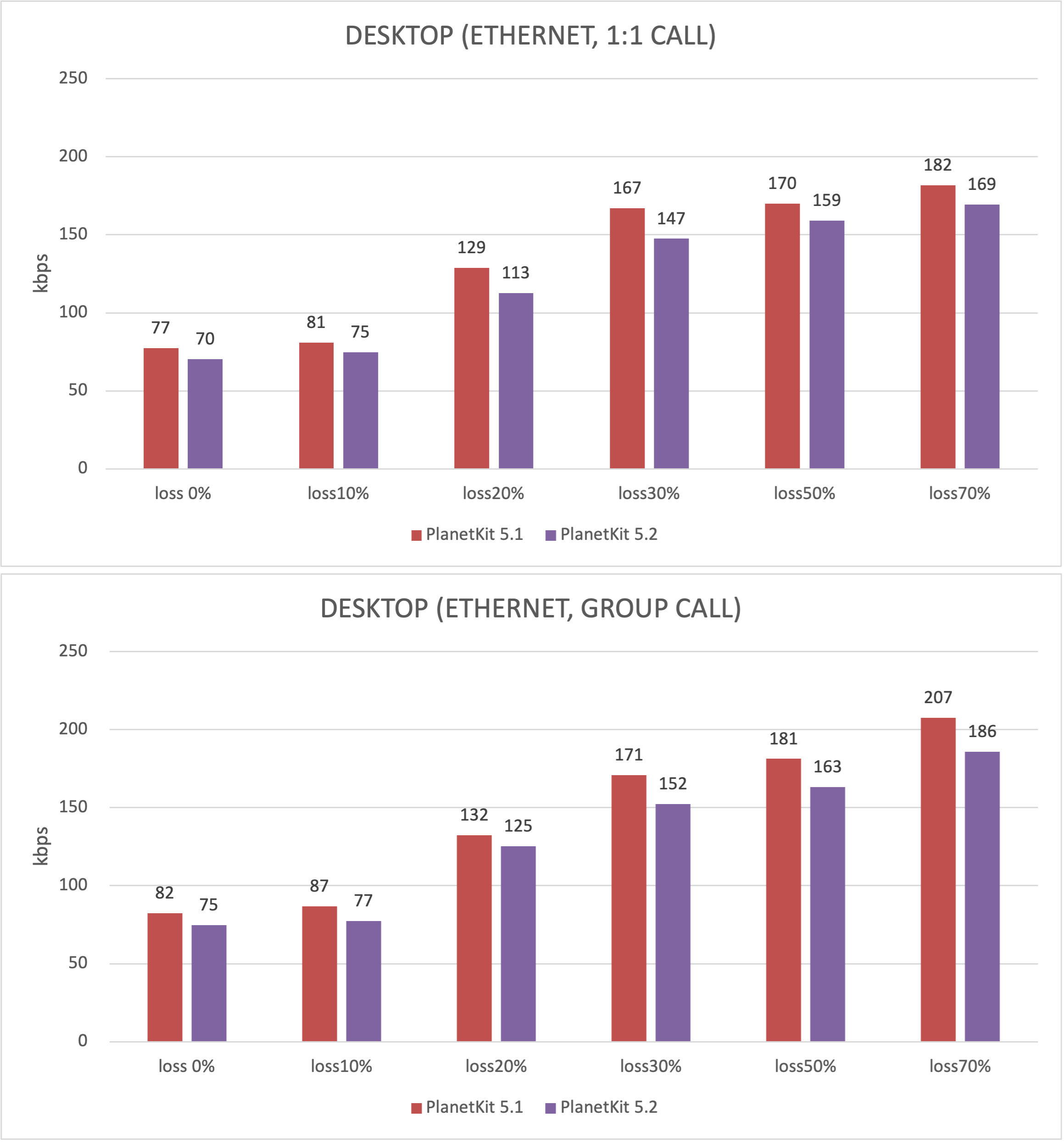
Summary of measurement results
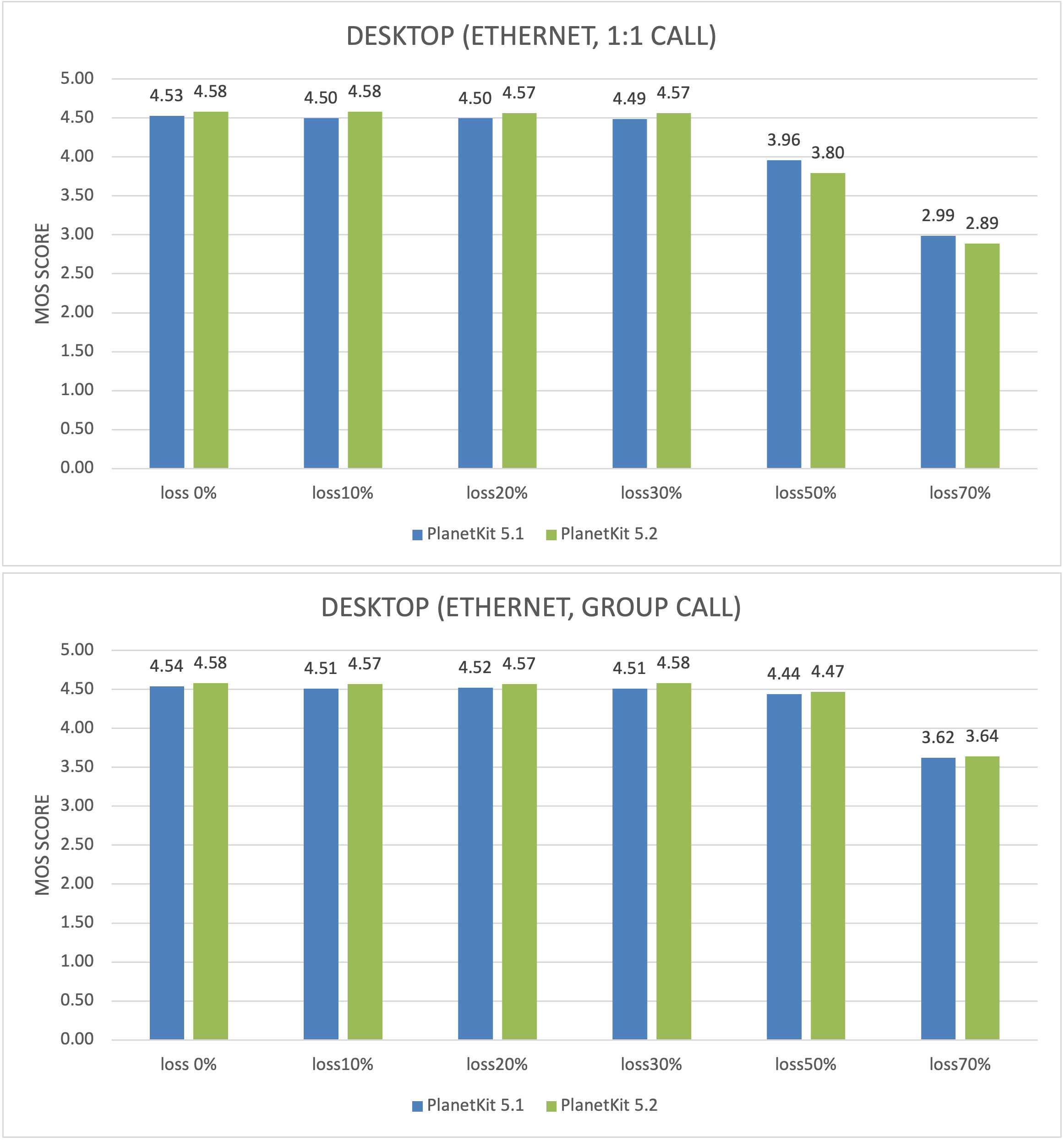
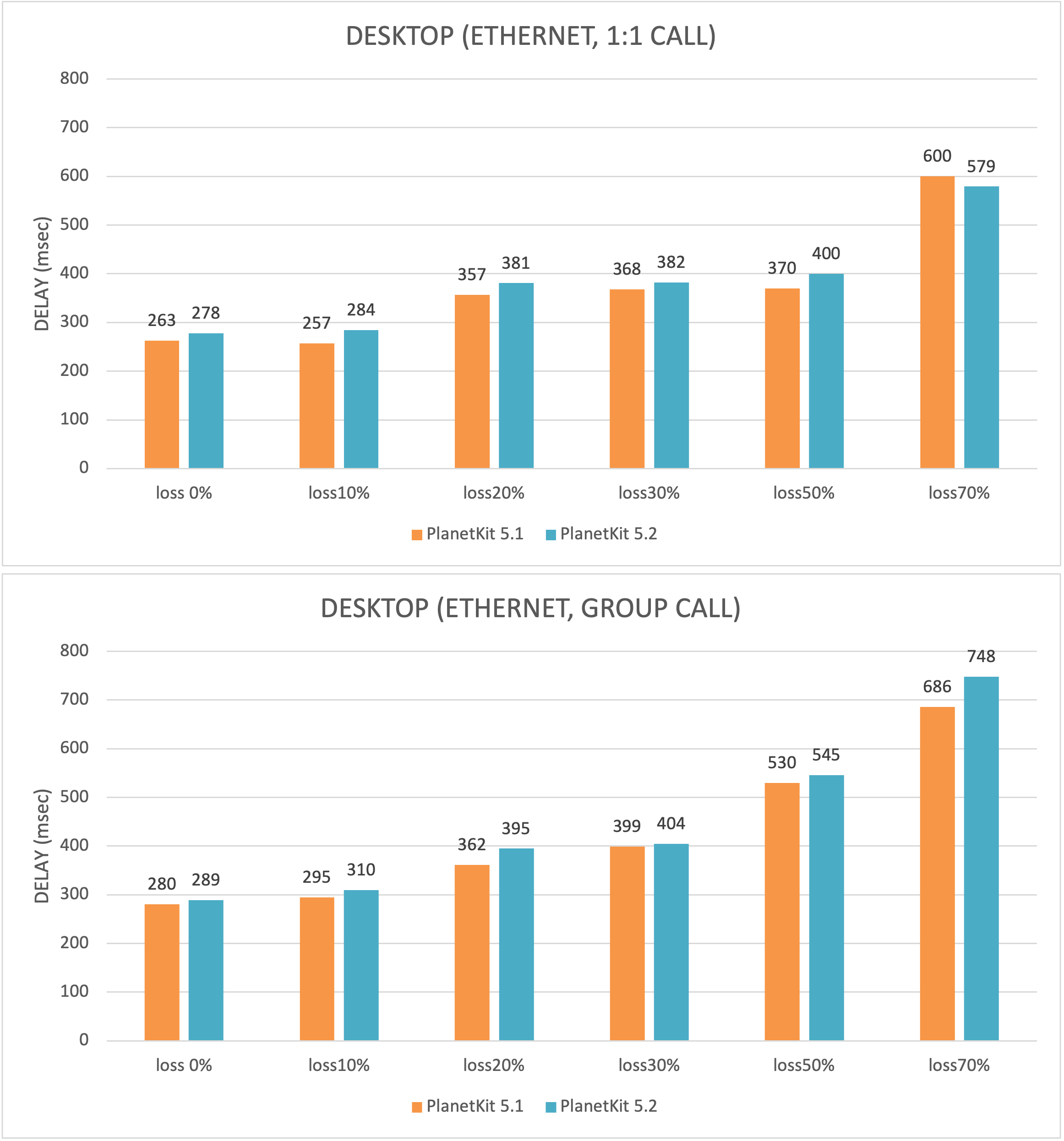
The data shown in the following figures are the results of 50 times of measurements for each metric, measured using DSLA equipment.
- POLQA MOS and one-way delay represent median.
- Data usage represents the average of the uplink bitrate of a device transmitting voice, measured by PacketStorm equipment.
Measurement result analysis
POLQA MOS
Similar to the previous version, up to a loss rate of 30%, voice quality has been fully restored to the point where it is measured at the same quality as in the case where there is no loss. Furthermore, at a loss rate of 50%, the user-perceived quality was excellent, with POLQA MOS scores of 3.80 and 4.47 for 1-to-1 calls and group calls, respectively.
It's notable that the POLQA MOS value for 1-to-1 calls tends to drop more significantly as the loss rate increases, compared to group calls. We believe this is due to differences in media paths between 1-to-1 calls and group calls. For group calls, the actions taken to recover from the loss by the media server placed between users prove beneficial for the recovery.
We can estimate the impact of loss recovery by comparing the difference in call quality depending on whether a loss recovery mechanism is in place. The following figure is a probability density function plot that compares a version of LINE without loss recovery with the latest version. The X-axis represents the MOS value, and the Y-axis represents the probability of that MOS value.
In the case where there is no loss recovery mechanism (red), most of the POLQA MOS values fall within the 2-point range even if the loss rate is only 10%. This can cause users to experience significant inconvenience, making calls almost impossible. On the other hand, when loss recovery is enabled (green), the lost voice data is effectively recovered, and POLQA MOS values of 4.5 or higher are achieved, facilitating smooth communication.
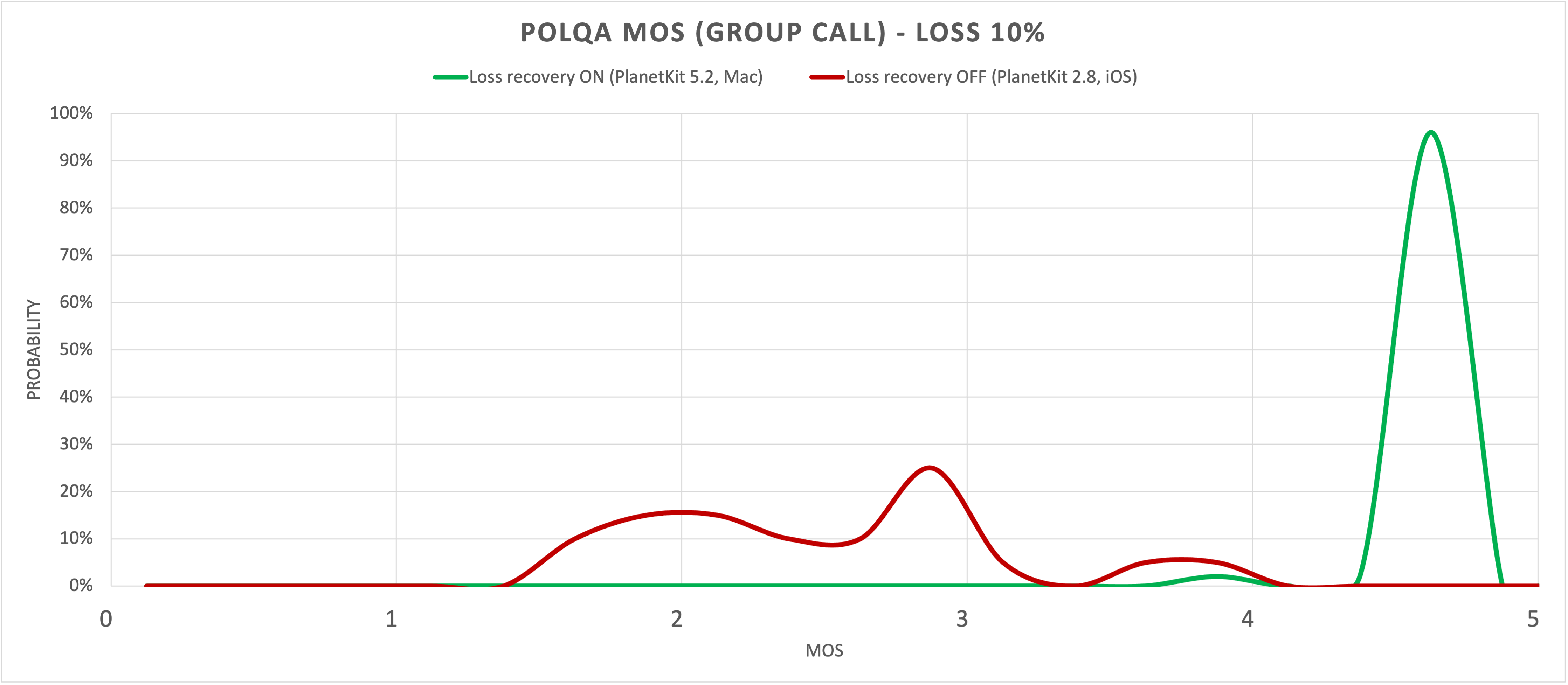
According to statistics from LINE's 1-to-1 calls, approximately 97% of all calls have a loss rate of up to 50%. This suggests that most of the degradation in voice quality caused by packet loss can be mitigated. However, when the loss rate exceeds 50%, there is a noticeable degradation in voice quality. For 1-to-1 calls, the POLQA MOS drops to 2.89 at a loss rate of 70%, which could potentially cause inconvenience during calls.
One-way delay
The one-way delay of voice tends to increase as the loss rate increases. In particular, in environments where the loss rate is 50% or higher, the one-way delay occasionally exceeds 500 milliseconds, which could cause inconvenience during calls.
In environments with very high loss rate, the loss recovery mechanism repeatedly attempts recovery, resulting in more buffering time for voice packets and thus increasing delay. If the one-way delay exceeds 500 milliseconds at a loss rate of 70% or higher for 1-to-1 calls, or 50% or higher for group calls, real-time conversation may become inconvenient.
Data usage
In general, as the loss rate increases, the number of packets required for recovery increases, so data usage also increases. PlanetKit 5.2 has been improved to generate fewer recovery packets than before, and this has the effect of reducing data usage by about 10% compared to the previous version. Even though data usage has been reduced, we can see that there is no adverse effect on POLQA MOS and one-way delay of voice.
Further works
Through this test, we have confirmed that PlanetKit 5.2 can facilitate smooth voice calls up to a 50% loss rate, demonstrating robustness in terms of network loss. Moreover, recent feature enhancements have allowed us to save approximately 10% of data while maintaining the call quality and latency.
However, if packet loss worsens and the loss rate reaches 70%, calls remain possible but the voice quality somewhat deteriorates and the one-way voice delay increases. Therefore, our goal is to make further improvements in this area. We are currently exploring new loss recovery mechanisms, taking into account network usage, one-way delay of voice, and loss recovery performance.
Conclusion
In this report, we provided a quantitative analysis of the call quality improvements in the recently updated PlanetKit 5.2 compared to the previous version, in terms of AEC, frequency response, and loss robustness.
For AEC, there have been improvements on all fronts. However, it seems that the quality needs to be improved further in situations where two people are speaking at the same time.
For frequency response, it was confirmed that the original sound was preserved almost entirely. Nevertheless, we anticipate that improving the attenuation between 7 kHz and 8 kHz will result in clearer speech.
For loss robustness, we discovered that we saved 10% of data usage without degrading voice quality and delay, compared to the previous version. However, it is preferable to improve one-way delay when the loss rate reaches 70%.
The testing method in this report follows the method of Measuring voice quality in the LINE app, which was posted separately on the LY Corporation Tech Blog.